
Логический шрифт
(Исправляем некорректное отображение кириллицы)
Введение
Итак,
вы сделали перевод любимой программы на русский язык, создали
локализованный файл, запустили приложение и, вдруг, вместо знакомых
символов видите какую-то несуразицу, типа "Ïðèâåò, ìû êðàêîçÿáëèêè!". Блин, что делать?
Самое простое решение — выполнить замену кодовых страниц в операционной
системе и добавить в реестр параметры подмены шрифтов. К сожалению,
такое решение является грубым и будет работать только на вашей системе.
Другие пользователи, воспользовавшись вашей работой, вместо текста на
русском увидят эту несуразицу и им также придется вносить изменения в
свою систему. Это в свою очередь может быть чревато негативными
последствиями для других приложений. Впрочем я не буду останавливаться
на этом подробно, а предлагаю вам решить проблему отображения символов
кириллицы более изящно — в самом файле приложения. Конечно для этого
нужны умение работы с отладчиком, знание API-функций и понимание
ассемблерных инструкций. Решение не из простых и потребует от вас
определенных навыков. Надеюсь, что это небольшое руководство поможет
вам самостоятельно справиться с этой проблемой.
Так почему же текст отображается некорректно?
Помимо статического шрифта, который конкретно задан в ресурсах
программы (в свойствах элементов управления, форм и диалогов), во время
работы любого приложения формируется еще логический шрифт, который
также используется для вывода надписей, строк и текста, например, при
динамической смене надписи на одном или нескольких элементах
управления. Любой из этих шрифтов характеризуется набором символов,
который задает кодировку текста: алфавит, цифры, знаки препинания.
Обычно вся продукция программного обеспечения использует
западно-европейский набор символов — ANSI_CHARSET. Десятичное значение этого набора равно 0 (в шестнадцатеричном формате — 0h) и ему соответствует кодировка windows-1252 (так называемая латиница). Посмотрите на рисунок 1, на нем представлена полная таблица с латинским набором символов:
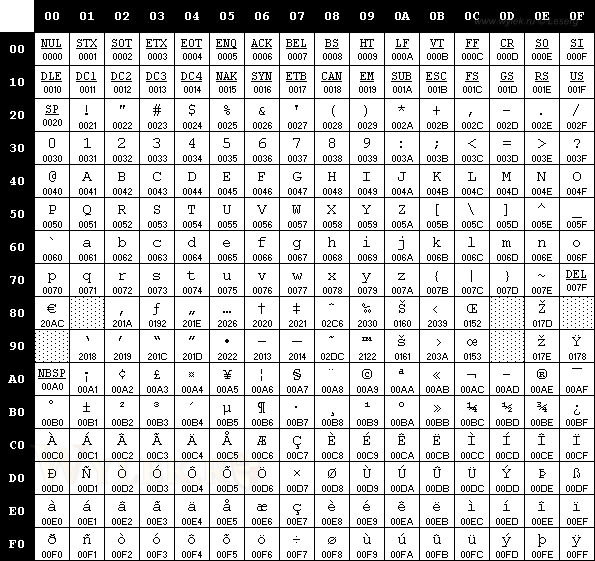 Рисунок 1 |
Хорошо видно, что этот набор не поддерживает символы кириллицы, и
поэтому, после локализации на русский язык, в программе повылазят "кракозяблики". Чтобы символы кириллицы были показаны корректно, необходимо использовать другой набор символов — RUSSIAN_CHARSET. Десятичное значение этого набора равно 204 (в шестнадцатеричном формате — ССh) и ему соответствует кодировка windows-1251 (так называемая кириллица). На рисунке 2 показана таблица с кириллическим набором символов:
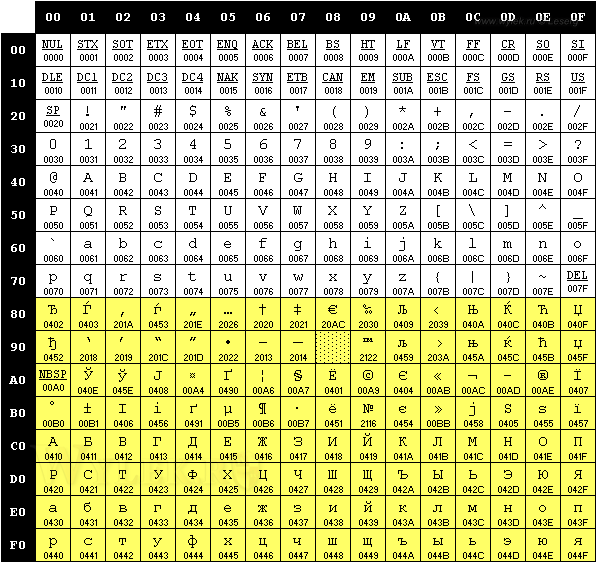 Рисунок 2 |
Символы кириллицы размещаются в нижней (второй) половине кодовой
страницы (на рисунке 2 показано желтым цветом). Если вы сравните оба
набора, то увидите, что они отличаются только нижней половиной, которая
является дополнительной (диапазон символов 80h — FFh).
Есть еще множество других наборов символов, к каждому из которых
привязана определенная кодовая страница, более подробно с ними вы
можете ознакомиться в справочной системе MSDN: "The Font Charset Property" и "Code Page Identifiers".
Кроме заданных наборов символов, в приложениях может быть использован неопределенный набор или набор по умолчанию — DEFAULT_CHARSET. Десятичное значение этого набора равно 1 (в шестнадцатеричном формате - 1h)
и он не соотвествует никакой кодировке. Другими словами это виртуальный
набор символов, который будет установлен и использован приложением в
зависимости от контекста устройства. Например, на системе с немецкой
локалью DEFAULT_CHARSET будет содержать набор символов ANSI_CHARSET. На системе с русской локалью DEFAULT_CHARSET будет содержать набор символов RUSSIAN_CHARSET. Вы можете в этом легко убедиться. Откройте в реестре ключ
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\FontMapper
и найдите там параметр DEFAULT. На системе с русской локалью значением для этого параметра будет ССh (204), что соответствует кириллическому набору символов, т.е. RUSSIAN_CHARSET.
Таким
образом, при локализации приложения, для всех элементов управления,
форм и диалогов, в свойствах шрифта достаточно указать вместо ANSI_CHARSET набор символов DEFAULT_CHARSET.
Если вы не уверены, что локализованное приложение будет использоваться
только на системах с русской локалью, то тогда укажите набор символов RUSSIAN_CHARSET. Этими действиями вы гарантируете корректное отображение статического текста в интерфейсе приложения.
Примеры исправления набора символов в ресурсах для различных типов приложений (касательно поддержки русского языка):
1) для приложений Delphi
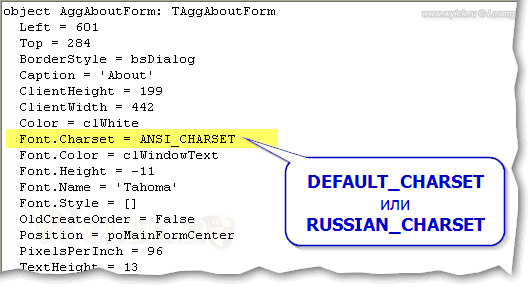 Рисунок 3 |
2) для приложений C/C++
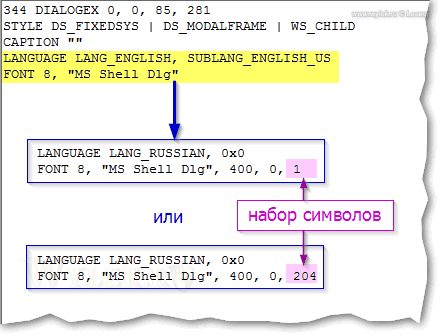 Рисунок 4 |
3) для приложений Visual Basic
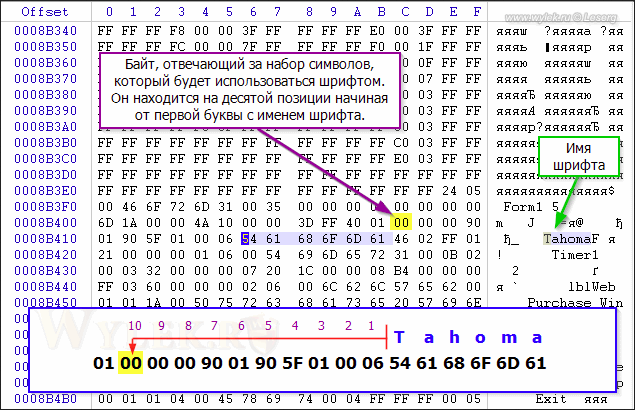 Рисунок 5 |
Обратите внимание, что байт, отвечающий за набор символов, находится на
десятой позиции начиная с первого символа с именем шрифта. Его
необходимо изменить на CCh.
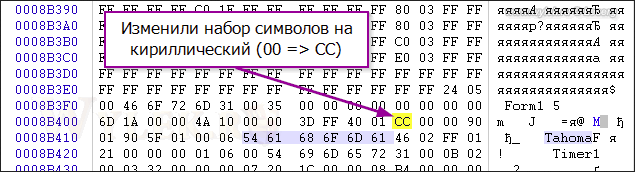 Рисунок 6 |
При локализации приложения обязательно обращайте внимание на
установленный набор символов, и при необходимости исправляйте его, как
показано в примерах выше. Это самая распространенная ошибка начинающих
локализаторщиков, когда делается перевод строк и совершенно упускается
из виду используемый приложением шрифт и набор символов, особенно при
использовании простейших программ по редактированию ресурсов, таких как
Resource Hacker, Restorator и других.
К
сожалению, исправление набора символов только в явных ресурсах
исследуемого приложения иногда бывает недостаточно. В процессе работы
программы строки могут считываться из других ресурсов, внешних или
внутренних, или каких-то других источников и в этом случае для их
вывода используется логический шрифт. За его создание отвечают
определенные API-функции, с которыми мы и познакомимся поближе.
1. Функция CreateFont
Имеет следующий синтаксис:
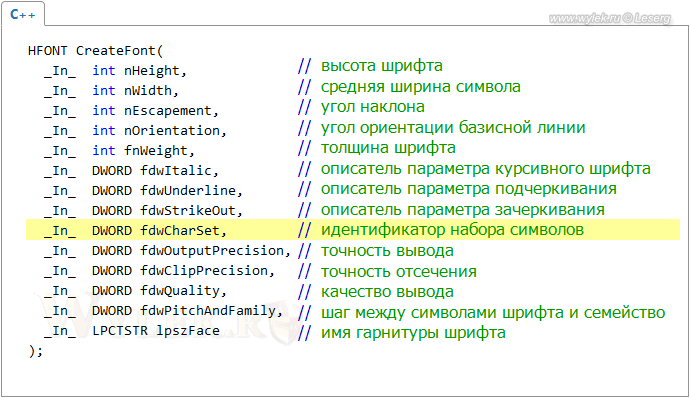 Рисунок 7 |
Более подробно с описанием каждого параметра вы можете ознакомиться в справочной системе MSDN: "CreateFont function".
Нас в первую очередь интересует параметр CharSet (на рисунке 7 выделен желтым цветом), который задает набор символов. Обычно, по умолчанию, значение этого параметра равно нулю (0), что соответствует набору символов ANSI_CHARSET. Иногда единица — DEFAULT_CHARSET. Могут, конечно, использоваться и другие наборы, например SYMBOL_CHARSET. Ваша задача: при помощи отладчика проверить все эти функции в коде приложения, и вот где задается набор символов ANSI_CHARSET, сделать исправление на DEFAULT_CHARSET или RUSSIAN_CHARSET. Проще всего исправлять набор символов на DEFAULT_CHARSET, т.к. его значение занимает размер 1 байт, а вот для значения RUSSIAN_CHARSET уже необходимо 4 байта. Сами понимаете, что в коде со свободным местом не разгонишься. Из своей практики скажу, что исправления набора символов на DEFAULT_CHARSET вполне достаточно. Заметьте, что правки требуют НЕ все функции CreateFont, а только те, которые некорректно выводят кириллический текст. Определить конкретную функцию, которая требует правки, можно только при работе с программой в отладчике.
Например, рассмотрим приложение GIF Construction Set (программа написана на Borland C++). При отладке локализованного файла программы в интерфейсе по вылазили кракозябры (см. рисунок 8).
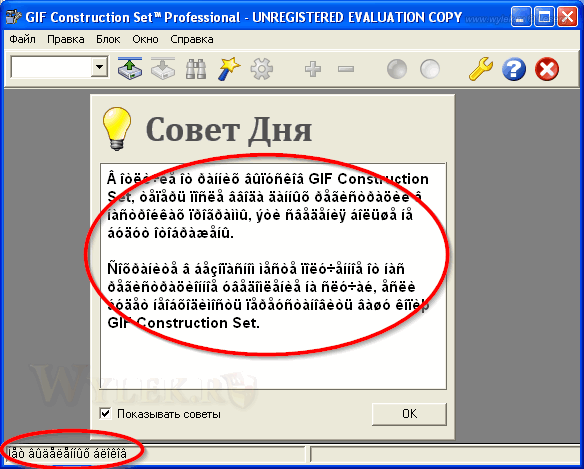 Рисунок 8 |
Если вы внимательно посмотрите на характер символов, то легко выявите их соответствие символам нижней половины кодовой страницы 1252 (см. рисунок 1). Грузим программу в отладчик (OllyDbg) и задаем поиск всех инструкций вызова Call. Для этого щелкните правой кнопкой мышки в окне дизассемблированного кода и выберите в контекстном меню команду "Search for -> All intermodular calls" (рисунок 9):
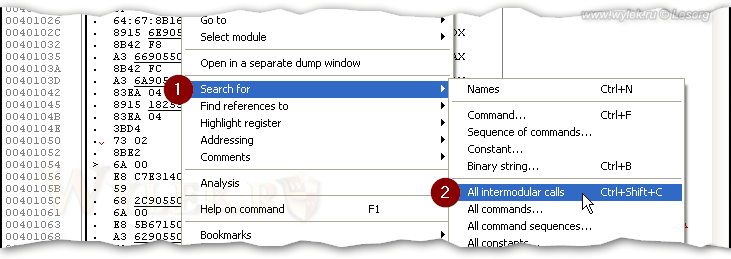 Рисунок 9 |
В списке найденных функций ищем CreateFont. Это будут функции CreateFontA и их будет много, не... очень много. Примечание: Символ 'А' в конце имени функций указывает на ANSI-версию функции, а символ 'W' — Unicode-версию функции.
Вы можете пощелкать левой кнопкой мышки по заголовкам таблицы, чтобы
отсортировать список в алфавитном порядке, так будет намного удобнее (рисунок 10).
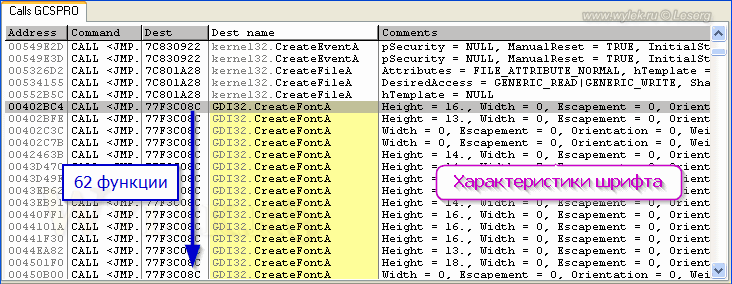 Рисунок 10 |
Аж
62 штуки! Кстати обратите внимание на столбец комментария напротив
каждой функции. В них перечисляются характеристики логического шрифта,
по которым он будет создан. Строка длинная и полностью не видна,
поэтому её лучше скопировать в блокнот и там уже нормально посмотреть.
Вот приведу вам одну строку:
Height
= 16., Width = 0, Escapement = 0, Orientation = 0, Weight =
FW_DONTCARE, Italic = FALSE, Underline = FALSE, StrikeOut = FALSE, CharSet = ANSI_CHARSET, OutputPrecision = OUT_DEFAULT_PRECIS, ClipPrecision = CLIP_DEFAULT_PRECIS, Quality = DEFAULT_Q... и т.д.
Ничего особенного не видите? Да, конечно же, параметр набора символов — CharSet = ANSI_CHARSET. Вот откуда растут ноги кракозябликов. Просмотрите все функции, почти во всех шрифт создается с латинским набором символов. Будем исправлять.
Сделайте двойной щелчок по первой функции и вы окажетесь в коде по адресу её вызова (рисунок 11):
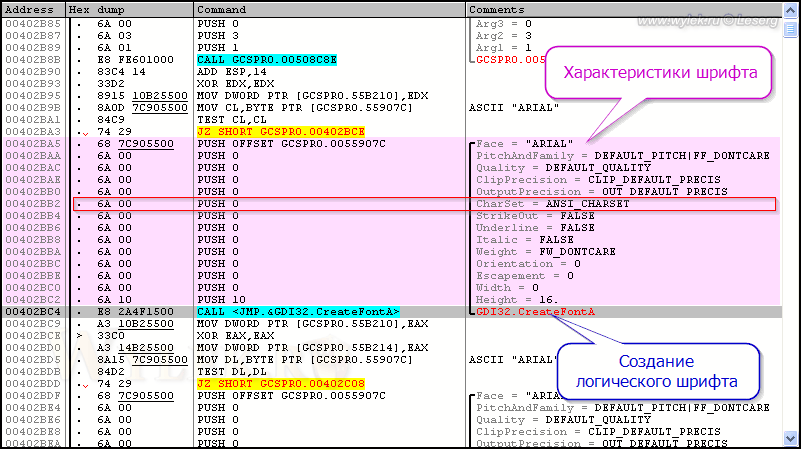 Рисунок 11 |
Ух, красота какая! Все параметры как на ладони. Но так бывает не очень часто, и скорее всего является частным случаем. Обычно параметры разбросаны и находятся не по порядку. Но это не страшно, потом, с обретением опыта, вы будете ориентироваться в коде без подсказок отладчика.
При исследовании функции CreateFont (как и CreateFontIndirect
— будет рассмотрена далее) обращайте внимание не только на набор
символов, но и имя шрифта. Ведь в программе могут использоваться шрифты
не только для вывода текста, но и также для формирования каких-то
сценариев, выражений и т.п. К примеру, функцию с такими параметрами
шрифта, как показано на рисунке 12,
не трогайте, она никакого отношения к кракозябрам не имеет. Если вы в
ней сделаете исправление, то можете угробить какую-нибудь важную
функцию. Обратите внимание, используется шрифт "Marlett" и набор символов SYMBOL_CHARSET:
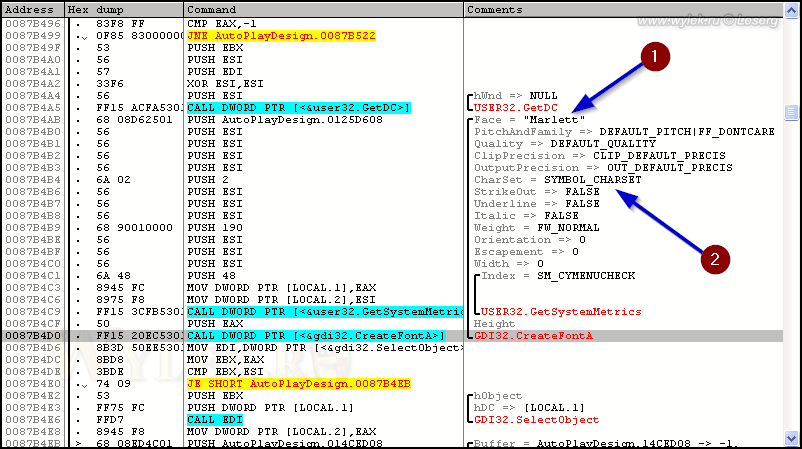 Рисунок 12 |
Идем дальше. Вы уже знаете, что набору символов ANSI_CHARSET спецификациями MSDN присвоено значение ноль (0). Посмотрите на следующий рисунок 13:
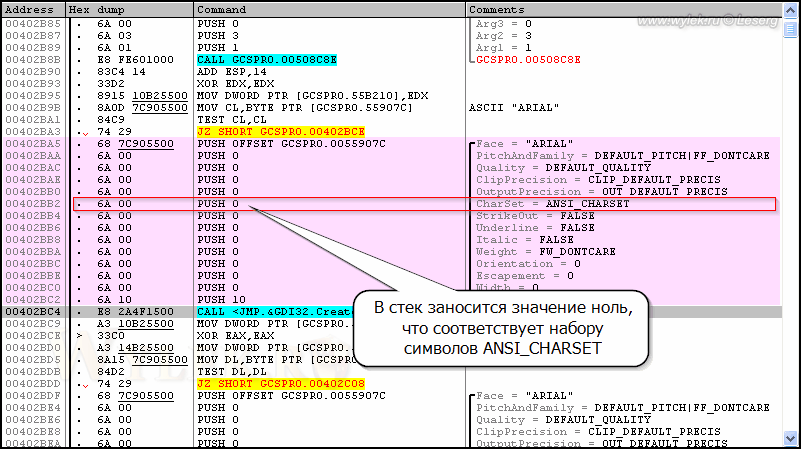 Рисунок 13 |
Здесь по адресу 00402ВВ2 записана инструкция PUSH 0 (6A 00), которая в данном контексте отвечает за параметр набора шрифта (CharSet). Как видите — это набор ANSI_CHARSET. Размер инструкции два байта: один байт собственно команда PUSH (6Ah), а другой байт значение 0 (0h). Проще всего изменить это значение на единицу, что будет соответствовать набору символов DEFAULT_CHARSET, т.е. сделать инструкцию вида PUSH 1 (6A 01). Для этого выделите строчку по адресу 00402ВВ2 и нажмите клавишу [Пробел]. В окошке введите PUSH 1 и нажмите "Assemble" (рисунок 14):
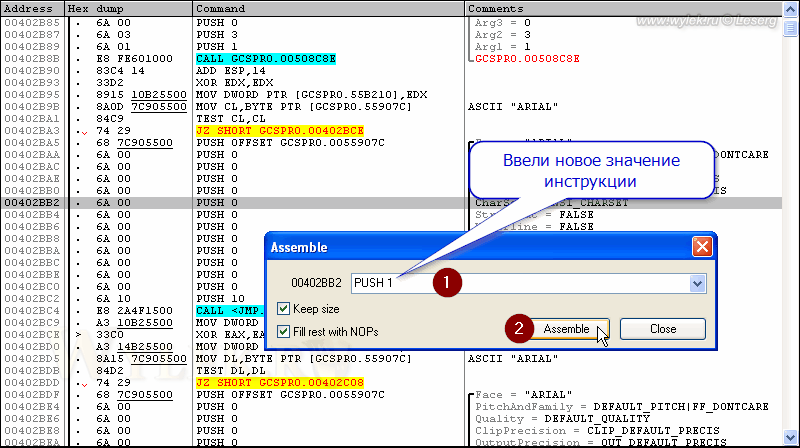 Рисунок 14 |
Вот теперь логический шрифт будет создан с набором символов по умолчанию (DEFAULT_CHARSET),
т.е. согласно установленной в операционной системе локали. Выполните в
отладчике повторный анализ кода, чтобы он скорректировал подсказки
после изменения кода (рисунок 15).
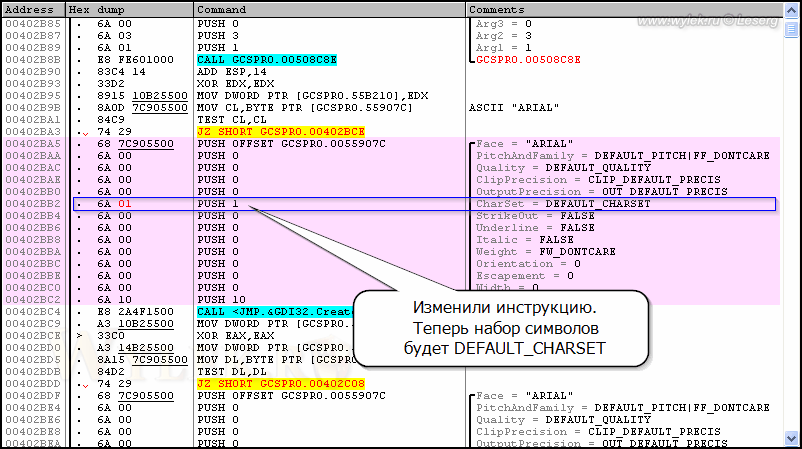 Рисунок 15 |
Теперь
запустите программу под отладчиком и внимательно изучите её интерфейс.
Пропали кракозяблики или нет (или пропали частично). Если изменение
параметров функции принесло положительный результат, то отметьте себе
где-нибудь адрес этой функции и переходите к следующей.
Подобным образом просматриваем все функции CreateFont и исправляем набор символов с ANSI_CHARSET на DEFAULT_CHARSET,
где это требуется. После сохранения сделанных правок кода в файл, и
последующего запуска программы, вы увидите корректное отображение
русских буковок.
Вы спрашиваете, а почему не RUSSIAN_CHARSET? Можно задать и этот набор символов, но дело том, что для значения 204 (ССh) требуется место размером 4 байта, в то время как для значения 1 необходим всего 1 байт. Вот посмотрите на сравнительную табличку (рисунок 16):
 Рисунок 16 |
В
последнем случае размер инструкции увеличился аж на 3 байта. Если
ввести такую инструкцию, то последующие инструкции по адресам 00402ВВ4 и 00402ВВ6 будут уничтожены (рисунок 17):
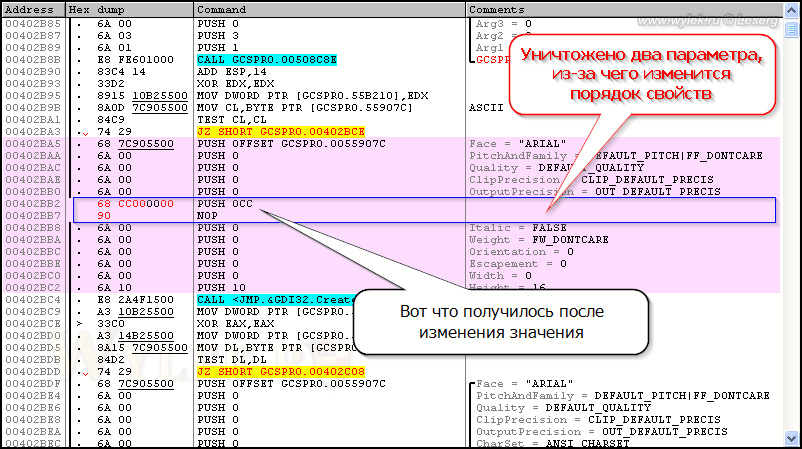 Рисунок 17 |
А так как функция принимает аргументы только в строго определенном порядке, то отсутствие некоторых из них может привести к программному сбою. Чтобы этого не случилось, нужно делать перенос кода в свободное место, восстановить там утерянные параметры, и вернуть выполнение программы в исходное место кода. Поэтому установки набора символов DEFAULT_CHARSET будет вполне достаточны.
Имейте
в виду, что значения для аргументов функции могут передаваться не
напрямую, как в представленном примере, а через стек, через выделенную
область памяти и т.д. Например, посмотрите на рисунок 18:
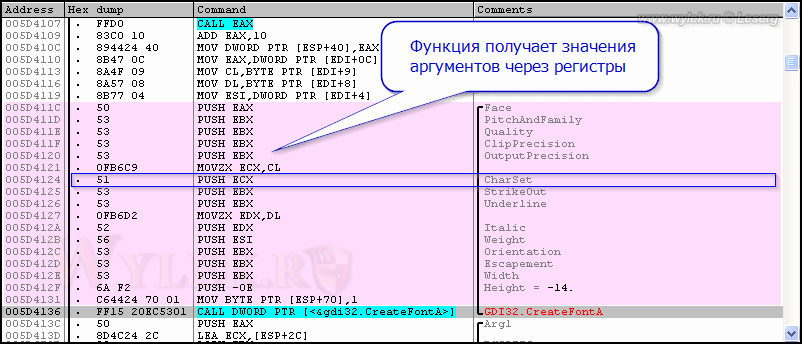 Рисунок 18 |
Да, вот в таких случаях придется делать перенос кода. Инструкции однобайтовые (например, PUSH ECX -> 51h — размер 1 байт), поэтому двухбайтовые, типа PUSH 1 -> 6A01h, уже не поместятся. Тогда, уже при переносе, уже можно будет указать набор символов RUSSIAN_CHARSET (если будет достаточно свободного места для ввода новых инструкций).
На практике, в программах, довольно часто характеристики шрифта формируются в памяти по определенному адресу, на который в последствии функции передается указатель. В таких случаях порядок параметров логического шрифта может быть каким угодно. Чтобы выяснить их принадлежность и выявить именно параметр CharSet, воспользуйтесь точками останова, исследуя формирование характеристик логического шрифта в пошаговом режиме до того, как они будут переданы в функцию CreateFont.
Теперь познакомимся с другой функцией, которая подобна CreateFont.
2. Функция CreateFontIndirect
Имеет следующий синтаксис:
 Рисунок 19 |
Более подробно с описанием каждого параметра вы можете ознакомиться в справочной системе MSDN: "CreateFontIndirect function".
С свою очередь структура LOGFONT определяет характеристики логического шрифта и имеет следующий синтаксис:
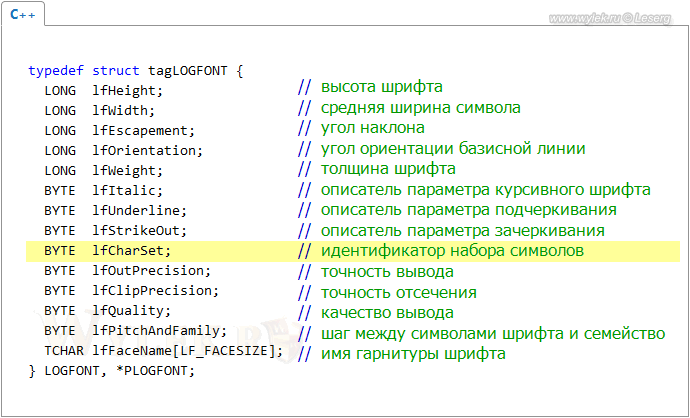 Рисунок 20 |
Здесь все параметры аналогичны параметрам функции CreateFont, за исключением того, что инициализация структуры LOGFONT может выполняться в другой части кода, а при вызове функции CreateFontIndirect будет указана только ссылка на неё. Хотя и с функцией CreateFont попадаются ситуации, когда характеристики шрифта раскиданы по коду, и найти среди них одну, отвечающую за набор символов, бывает не просто.
Например, рассмотрим плагин "Engraver III" (программа написана на Visual C/C++) для графического редактора Adobe Photoshop. После локализации файла плагина и его загрузки в редактор вашему взору предстанут кракозяблики (в списках, заголовках вкладок, на кнопках).
 Рисунок 21 |
Принцип действий аналогичен описанному выше примеру: под отладчиком необходимо проверить функции CreateFont и CreateFontIndirect. Можно загрузить файл плагина (.8bf) напрямую, но лучше присоединиться к запущенному процессу с этим плагином, тогда вы сможете на лету увидеть сделанные исправления.
Итак, запустите редактор Photoshop (или какой-то другой редактор, который поддерживает такой формат плагинов) и откройте в нем окно плагина. После этого перейдите в отладчик (OllyDbg) и, используя в меню "File" пункт "Attach...", загрузите процесс с именем редактора (рисунок 22):
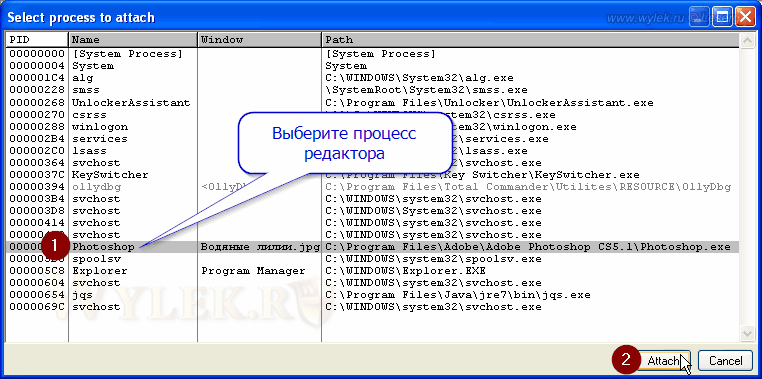 Рисунок 22 |
Откройте карту памяти, найдите там процесс с именем плагина и загрузите секцию с кодом (.text) в окно дизассемблера (при помощи команды в контекстном меню — рисунок 23):
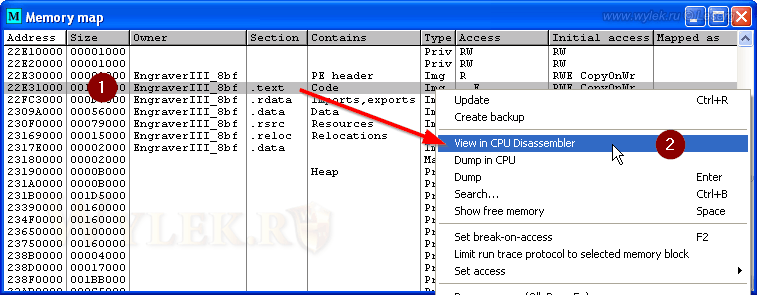 Рисунок 23 |
Теперь задайте поиск всех инструкций Call. В полученном списке найдите функции CreateFont и CreateFontIndirect. В нашем плагине имеется всего лишь одна функция CreateFontIndirectA (рисунок 24):
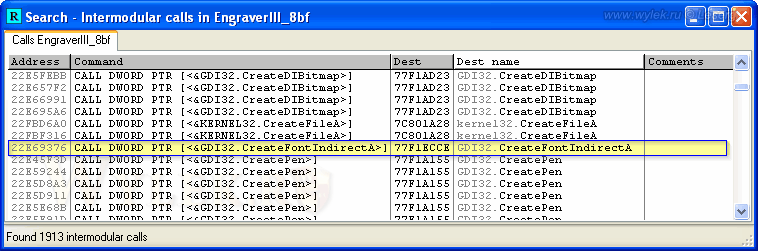 Рисунок 24 |
Да уж, не густо. Но это не значит, что она там одна. Вызов функций может быть осуществлен не напрямую, посредством имени функции, а косвенно, через указатель на адрес в памяти, по которому она загружена. Пока же перейдем на адрес 22E69376 по месту вызова функции и посмотрим на параметры, которые она принимает (рисунок 25).
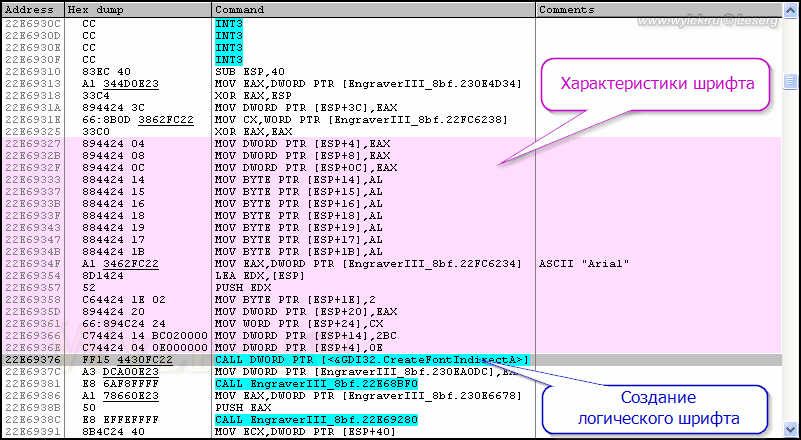 Рисунок 25 |
О-о, здесь из всех свойств понятным является только имя шрифта, а для остальных ничего не известно. К тому же, как видно из инструкций, все параметры записываются по определенным адресам в памяти, значения для которых берутся из регистров. Сам адрес берется из регистра ESP, к которому, соответственно для каждого параметра, прибавляется определенное смещение. Это смещение в свою очередь определяет порядок, с которым параметры будут поступать на вход функции. Нам нужно определить, по какому смещению записывается параметр с набором символом и, конечно же, изменить его.
Для начала определим, смещение нужного нам байта, который устанавливает набор символов. Для этого поставьте точку останова на адрес вызова функции CreateFontIndirectA (22E69376). Теперь перейдите в редактор, закройте окно плагина и откройте его снова. Выполнение программы прервется на точке останова и в окошке стека можно увидеть, какие данные поступят на вход функции (строка длинная, поэтому её лучше скопировать в блокнот — рисунок 26).
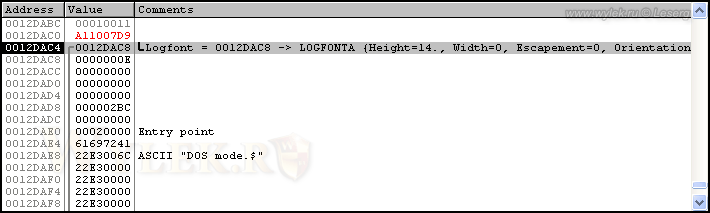 Рисунок 26 |
Вот эта строка почти полностью:
LOGFONT
= 0012DAC8 -> LOGFONTA {Height = 14., Width = 0, Escapement = 0,
Orientation = 0, Weight = FW_BOLD, Italic = FALSE, Underline = FALSE,
StrikeOut = FALSE, CharSet = ANSI_CHARSET, OutPrecision = OUT_DEFAULT_PRECIS, ClipPrecision = CLIP_DEFAULT_PRECIS, Quality = PROOF_QUAL... и т.д.
Она вам уже знакома по функции CreateFont. Отличается только тем, что параметры шрифта заданы структурой LOGFONT. Хорошо видно, что шрифт будет создан с латинским набором символов CharSet=ANSI_CHARSET. Но пока он еще не создан, имеет смысл поискать смещение с этим параметром.
В окне стека (см. рисунок 26), в колонке "Value", показан адрес, по которому в данный момент находятся характеристики будущего шрифта — 0012DAC8 . Щелкните по нему правой кнопкой мышки и в контекстном меню выберите команду "Follow in Dump". В окно дампа будут загружены данные памяти с указанного адреса (рисунок 27):
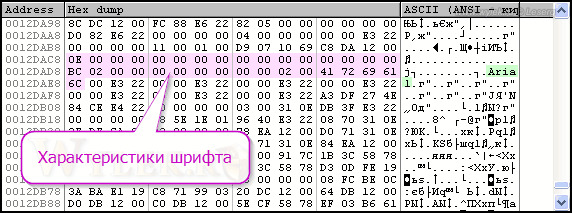 Рисунок 27 |
Здесь сиреневым цветом выделена область с данными характеристик логического шрифта. Как здесь ориентироваться? Да очень просто! Вспомните синтаксис команды (см. рисунок 20): первый параметр это высота шрифта, а последний — имя шрифта. Смотрим, по адресу 0012DAC8 первый байт идет 0Eh — это высота. Далее в текстовой части дампа ищем имя шрифта. Есть такое — Arial — последний параметр. Между первый байтом и байтами с именем шрифта находятся все остальные параметры. Если считать параметры от имени шрифта, то идентификатор набора символов будет пятым по счету. Почему? Снова вспоминайте синтаксис, там указан размер, который занимает каждый из параметров. Сам параметр с набором символов имеет размер 1 байт (BYTE) и все остальные параметры, до параметра с именем шрифта, также имеют размер в 1 байт соответственно. Считать, надеюсь, вы умеете. От первого байта с именем шрифта отсчитайте назад 5 байт и вы получите размещение байта, который отвечает за набор символов — адрес 0012DADF (рисунок 28).
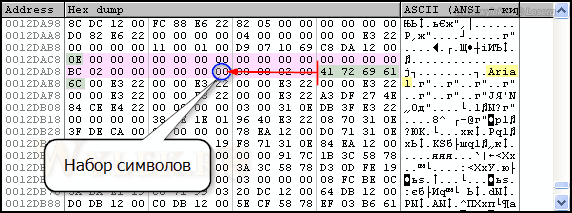 Рисунок 28 |
Хорошо, а как узнать смещение и инструкцию, которая записывает значение набора символов по этому адресу? Если вы посмотрите на инструкции формирующие массив с характеристиками шрифта, то увидите, что данные записываются в память относительно адреса, который в текущий момент находится в регистре ESP. Обычно этот адрес указан в стеке перед вызовом функции (см. рис. 26, колонка "Address"). Но так бывает не всегда, как, например, в данном случае. Сейчас там записан адрес 0012DAC4. Но буквально перед переходом на адрес вызова функции адрес в регистре ESP был другой, а именно - 0012DAC8. Это можно выяснить пройдя в пошаговом режиме все инструкции с установкой характеристик шрифта. Поэтому, зная адрес 0012DAC4 и адрес, по которому записано значение набора символов — 0012DADF, можно легко вычислить размер смещения. При помощи калькулятора Windows в режиме НЕХ-вычислений выполните арифметическое действие:
0012DADF – 0012DAC8 = 17
Это и есть размер смешения. Смотрим на инструкции с установкой характеристик шрифта и ищем среди них значение 17h. Есть такое, по адресу 22E69347. Здесь находится инструкция MOV BYTE PTR [ESP+17],AL, которая записывает содержимое регистра AL на определенный адрес в памяти [ESP+17] (рисунок 29).
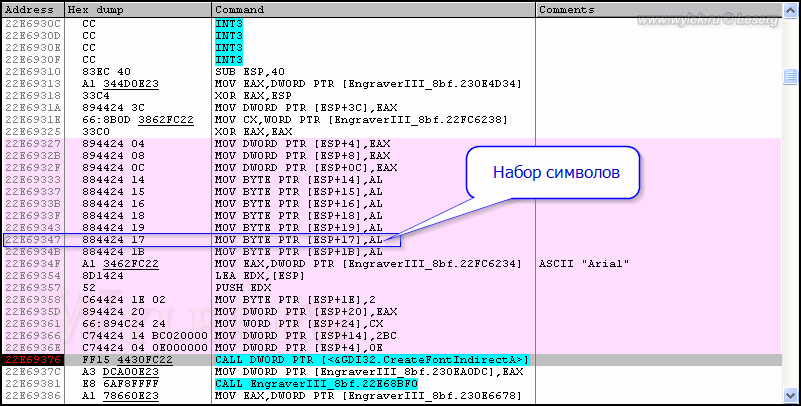 Рисунок 29 |
Прежде чем ломать голову над тем, как вместо AL записать значение нужного нам набора символов, вы можете проверить, а стоит ли здесь вообще что-то делать, может причина кракозябликов не в этом участке кода. Если помните, то программа с плагином у нас запущена, но их работа приостановлена в точке останова перед вызовом функции. Сейчас в дампе памяти можно изменить значение набора символов. В окне дампа памяти выделите байт по адресу 0012DADF, откройте редактор двоичных значений (клавиши [Ctrl+E]) и ведите в поле НЕХ значение 01h вместо 00h (рисунок 30).
 Рисунок 30 |
Подтвердите ввод. Получится вот так:
 Рисунок 31 |
Перейдите в окно стека и проверьте параметр CharSet. Теперь он будет равен DEFAULT_CHARSET. Вот часть строки с этим параметром:
Logfont
= 0012DAC8 -> LOGFONTA {Height = 14., Width = 0, Escapement = 0,
Orientation = 0, Weight = FW_BOLD, Italic = FALSE, Underline = FALSE,
StrikeOut = FALSE, CharSet = DEFAULT_CHARSET, OutPrecision = OUT_DEFAULT_PRECIS, ClipPrecision = CLIP_DEFAULT_PRECIS, Quality = PROOF_Q... и т.д.
Продолжите выполнение программы, нажав клавишу [F9]. Перейдите в окно редактора и внимательно изучите окно плагина, изменилось ли в нем что-то. Да, изменилось! Надписи на кнопках стали отображаться корректно!
 Рисунок 32 |
Значит мы на верном пути. Правда еще остались списки и заголовки вкладок. Как быть с ними, ведь таких функций больше нет? Попробуем поискать по имени шрифта. Предположим, что автор везде использовал шрифт Arial. Строка "Arial" является жестко-закодированной, поэтому поищем на неё ссылки. Щелкните в отладчике по строке с адресом 22E6934F, по которому записана инструкция установки имени шрифта и в контекстном меню выберите команду "Find references to -> Address constant" (рисунок 33):
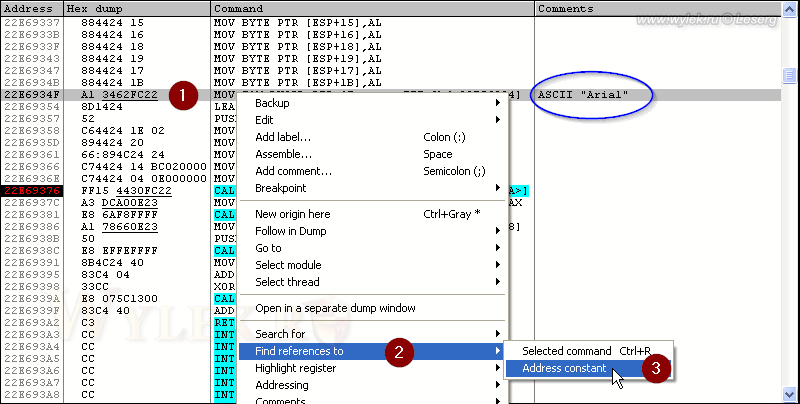 Рисунок 33 |
Откроется список ссылок (если таковые будут):
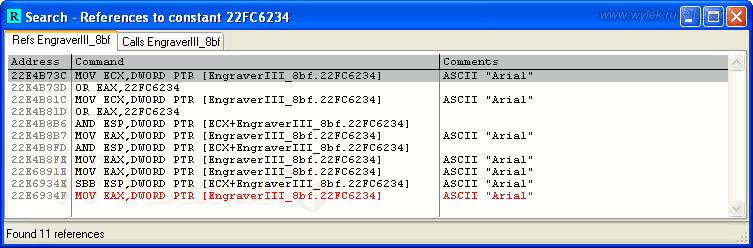 Рисунок 34 |
Строка, выделенная шрифтом красного цвета, указывает на нашу позицию в окне дизассемблера. Перейдем по адресу 22E4B73C (первая строка в списке ссылок). Посмотрите на рисунок 35:
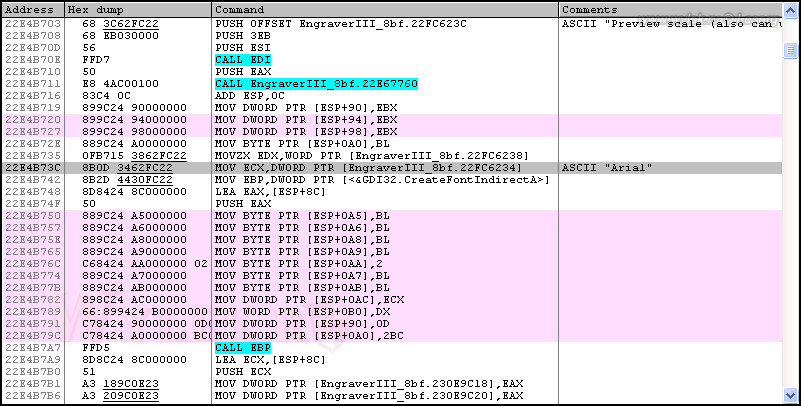 Рисунок 35 |
Где-то мы уже подобное видели... Ничего не напоминает? Снова в памяти, относительно адреса в регистре ESP, формируется массив с характеристиками шрифта (на рисунке 35 выделено светло-фиолетовым цветом), после чего выполняется вызов функции CreateFontIndirectA. Только её вызов сделан через регистр EBP. Вернитесь к рисунку 35 и посмотрите еще раз. По адресу 22E4B742 в регистр EBP заносится адрес, по которому находится сама функция. т.е. обращение организовано не напрямую, а через регистры, в данном случае EBP. Далее, по адресу 22E4B742, идет обращение к нашей функции (CALL EBP). По остальным параметрам здесь все аналогично примеру, разобранному чуть выше. Сразу скажу, что параметр набора символов задается только в первом блоке логического шрифта, который показан рисунке 35. В дальнейшем формируются шрифты с различными характеристиками, но набор символов не изменяется. Это станет понятно, если вы пролистаете дизассемблированный код ниже и выполните его визуальный анализ.
Ну что же, поищем здесь инструкцию, которая устанавливает набор символов. Алгоритм действий аналогичен предыдущему случаю. Устанавливаем точку останова по адресу 22E4B7A7 — вызов функции CreateFontIndirectA (предыдущую точку останова временно отключите), перезапускаем в редакторе плагин и отладчик приостановит его выполнение по указанному адресу. Перейдите в окно стека, а оттуда откройте в окне дампа адрес с характеристиками шрифта. Ориентируясь по имени шрифта найдите адрес, по которому записано значение набора символов. Это будет адрес 0012D597. В регистре ESP в данный момент находится адрес 0012D4F0 и относительно него в памяти формировался массив с характеристиками шрифта. Поэтому вычисляем размер смещения
0012D597 - 0012D4F0 = A7
Ищем это смещение в ближайших инструкциях и находим его по адресу 22E4B774 (см. рисунок 35). Здесь находится инструкция MOV BYTE PTR [ESP+0A7],BL, которая записывает содержимое регистра BL на определенный адрес в памяти [ESP+0A7]. Чтобы удостовериться в наших расчетах, изменим в дампе памяти по адресу 0012D597 значение 00h на 01h. В окне стека проверим характеристики шрифта. Теперь параметр CharSet имеет значение DEFAULT_CHARSET. Продолжим выполнение программы, нажав клавишу [F9].
 Рисунок 36 |
Отлично! Вы видите, что теперь все строки в окне приложения отображаются корректно.
Итак, мы выяснили, что в код плагина необходимо внести изменения по адресам 22E69347 и 22E4B774, где записаны следующие инструкции (соответственно):
MOV BYTE PTR [ESP+17],AL | 88 44 24 17
и
MOV BYTE PTR [ESP+0A7],BL | 88 9C 24 A7 00 00 00
Как было сказано ранее, набор символов можно устанавливать DEFAULT_CHARSET, которому соответствует значение 1. Но если мы запишем в инструкции вместо AL (BL) единицу, то размер инструкции увеличится на 1 байт. Поэтому придется записать инструкцию на свободном участке кода и сделать на неё переход. Свободное место обычно есть в конце первой секции. Дизассемблированый код первой секции как раз открыт у нас в отладчике. Если опуститесь в конец кода, то увидите там нулевые байты. Но прежде чем туда что-то писать, нужно сначала удостовериться, что свободное место там есть физически. Станьте на начало нулевого кода после последней инструкции и откройте дамп памяти по этому адресу, воспользовавшись командой контекстного меню "Follow in Dump -> Selection" (рисунок 37):
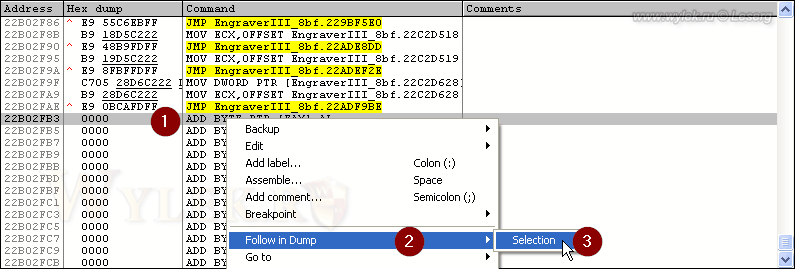 Рисунок 37 |
В окне дампа будет открыта эта область памяти. Здесь можно визуально оценить размер пустой области (рисунок 38). Также это можно узнать, если исследовать файл в НЕХ-редакторе.
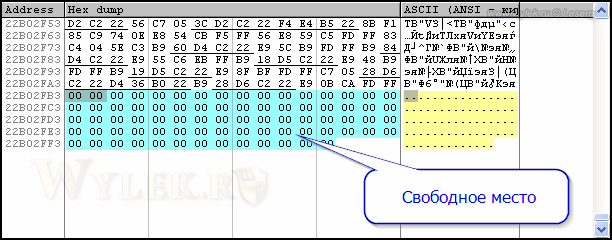 Рисунок 38 |
Не много, но для решения нашей задачи этого будет достаточно. Переносим код по адресу 22E69347. Вместо инструкции MOV BYTE PTR [ESP+17],AL нам нужно записать MOV BYTE PTR [ESP+17],1. В окне дизассемблера устанавливаем курсор на строку с адресом 22B02FB3 (начало пустой области), нажимаем клавишу [Пробел] и вводим в поле новую инструкцию. Подтверждаем команду клавишей "Assemble" (рисунок 39).
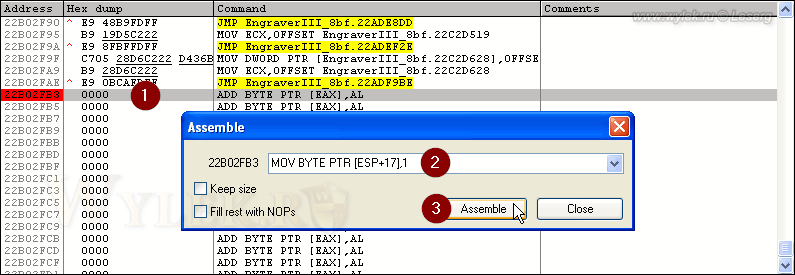 Рисунок 39 |
Теперь скопируем следующую инструкцию по адресу 229A934B (MOV BYTE PTR [ESP+1B],AL) и вставим её по адресу 22B02FB8, следом за только что вставленной. Это необходимо вот для чего (см. рисунок 40). На месте исходных инструкций мы будем делать переход при помощи инструкции JMP. Она занимает 5 байт, а у нас там для одной инструкции доступно только 4 байта. Поэтому 1 байт инструкция перехода заберет у следующей инструкции, т.е. она будет просто испорчена. Вот поэтому мы её и восстановим по месту переноса.
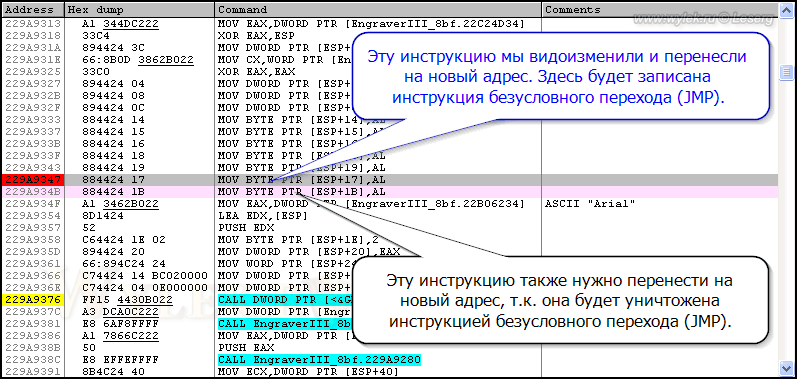 Рисунок 40 |
У вас должно получиться вот так:
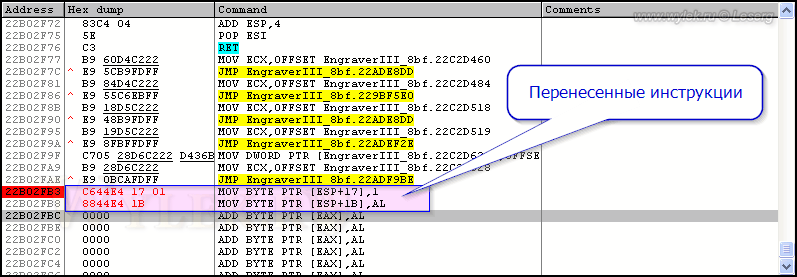 Рисунок 41 |
Теперь организуем безусловный переход с основного участка кода на видоизменённый и обратно. По адресу 22E69347, в месте оригинального кода вставим инструкцию JMP с адресом по месту размещения нового кода, а именно 22B02FB3 (рисунок 42):
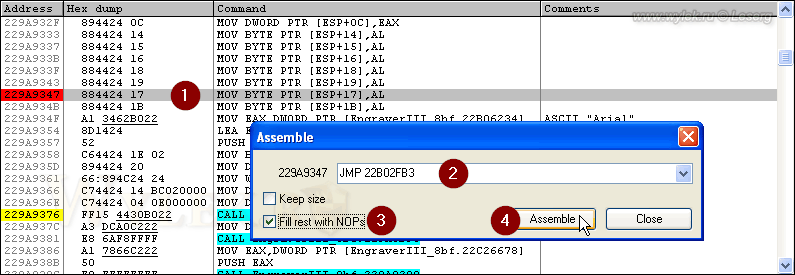 Рисунок 42 |
Не забудьте отметить опцию "Fill rest with NOPs" (заполнить остаток инструкциями NOP), чтобы избавится от мусора испорченных инструкций. Получится вот так:
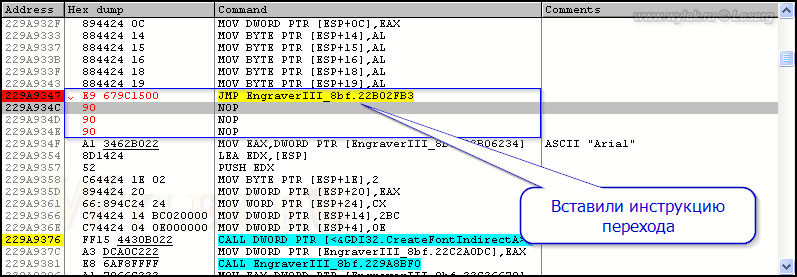 Рисунок 43 |
Хорошо видно, что инструкция перехода захватила последующую инструкцию. Теперь по месту добавленных инструкций нужно добавить инструкцию возврата в основной код программы. Возврат также выполняется инструкцией безусловного перехода JMP. Адрес возврата можно взять 229A934C, который идет следом за вставленной инструкцией перехода, а можно использовать адрес 229A934F, по которому продолжается основной код программы. Воспользуемся вторым вариантом, т.к. по адресам 229A934C, 229A934D и 229A934E находятся пустые инструкции и нет смысла делать на них возврат. Переходим к адресу 22B02FBC по месту размещения добавленных нами инструкций, и вводим инструкцию возврата (рисунок 44):
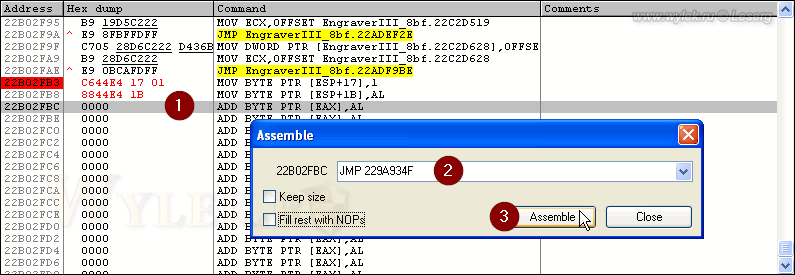 Рисунок 44 |
У вас должно получиться вот так:
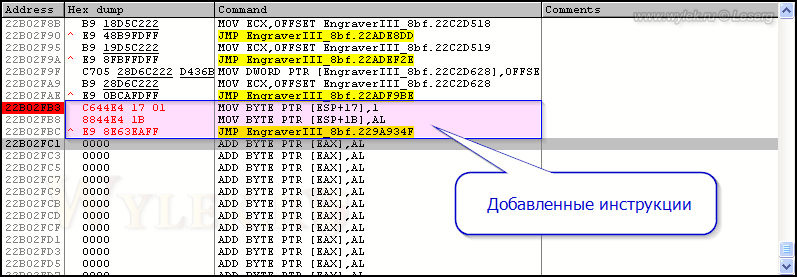 Рисунок 45 |
Таким образом мы организовали формирование набора символов с нужным нам значением для одной из функций CreateFontIndirect. При работе плагина, процесс выполнения кода, дойдя адреса 22E69347, перейдет на добавленные нами инструкции по адресу 22B02FB3. Выполнит их, затем вернется обратно на основной участок кода и продолжит выполнение плагина. Надеюсь, смысл, сделанных нами манипуляций, вам понятен.
Аналогичную операцию нужно провести для другой функции CreateFontIndirect. По адресу 22E4B774 изменим инструкцию и перенес её на новое место. Вместо MOV BYTE PTR [ESP+0A7],BL необходимо ввести MOV BYTE PTR [ESP+0A7],1. Перейдем в окне дизассемблера на адрес 22B02FC1, который следует за введенными нами данными ранее, и запишем здесь (рисунок 46):
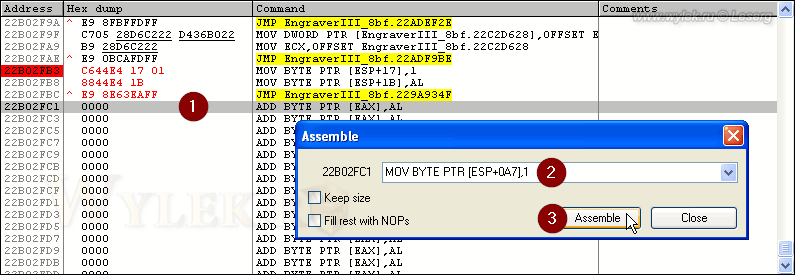 Рисунок 46 |
Теперь организуем переход. Другие инструкции переносить в этом случае не нужно, т.к. размера оригинальной инструкции достаточно для ввода инструкции безусловного перехода. Итак, идем на адрес 22E4B774 и вводим инструкцию JMP 22B02FC1 (рисунок 47):
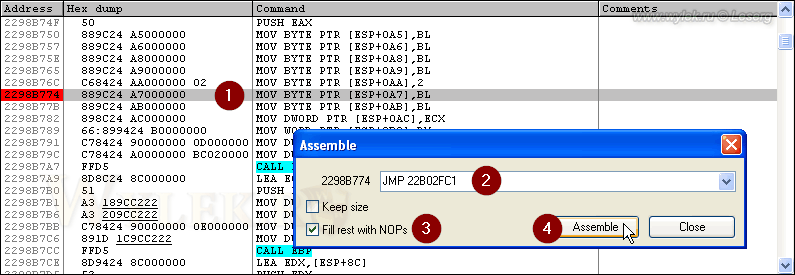 Рисунок 47 |
После подтверждения команды, код изменится следующим образом:
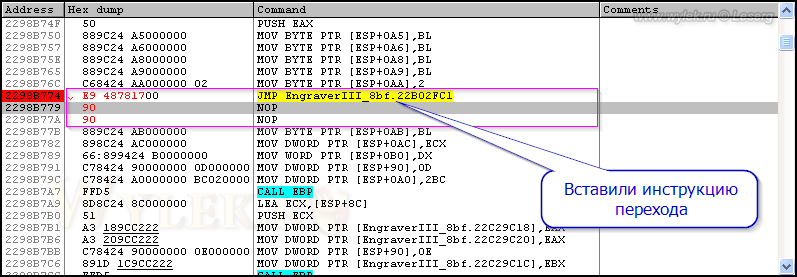 Рисунок 48 |
Как видите, инструкция перехода заняла место предыдущей инструкции. А так как её размер ещё и меньше, то в оставшиеся два байта были записаны пустые команды. Возврат с дополнительного участка кода нужно сделать на адрес 2298B77B. Так и запишем:
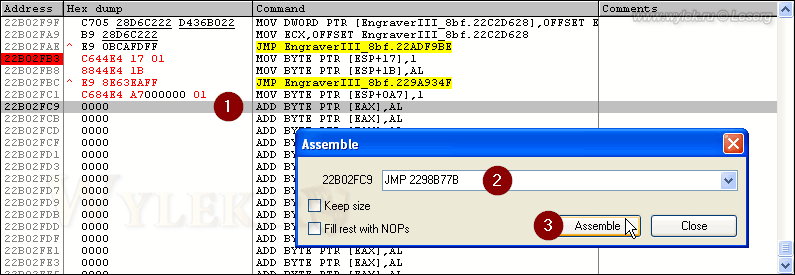 Рисунок 49 |
В итоге, в конце первой секции файла плагина будет находиться созданный нами код, который будет записывать для параметра CharSet необходимый нам набор символов (рисунок 50):
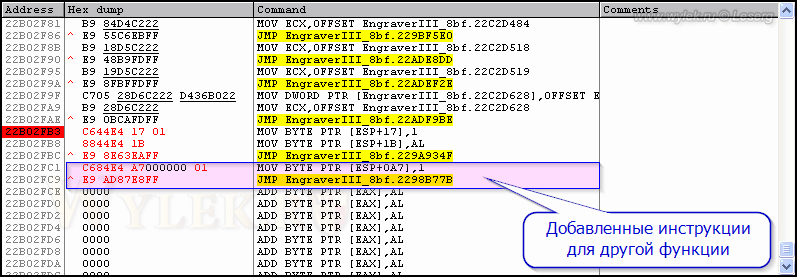 Рисунок 50 |
Готово. Осталось только сохранить сделанные изменения в файл. Щелкаем правой кнопкой в окне дизассемблера и выбираем в контекстном меню команду "Edit -> Copy all modifications to executable":
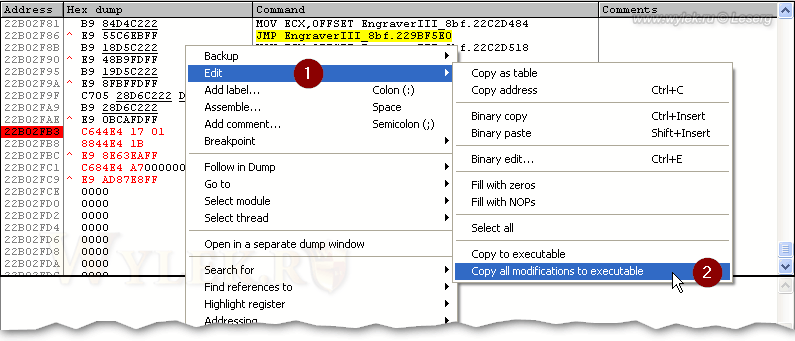 Рисунок 51 |
В открывшемся окне снова пользуемся контекстным меню, в котором выбираем пункт "Save file...", и сохраняем файл под другим именем (рисунок 52):
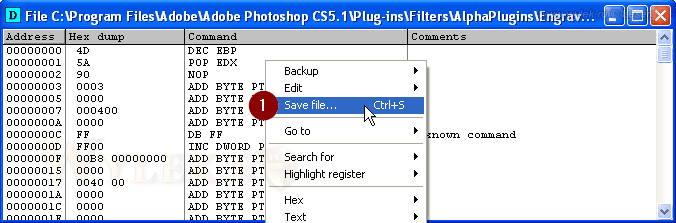 Рисунок 52 |
После этого проверяете его работу, не забывая сделать резервную копию исходного файла. Если вы нигде не ошиблись, то увидите текст в читабельном виде.
До этого мы рассматривали исправление набора символов в функциях 32-бит приложений. А как обстоит дело в 64-бит? Не беспокойтесь, там все аналогично за исключением того, что дизассеблироанные инструкции имеют несколько иной вид, но так и должно быть. Так как отладчик OllyDbg не поддерживает приложения с архитектурой 64-бит, то рекомендую использовать отладчик x64dbg (http://x64dbg.com/). Он очень похож на OllyDbg и взял от него все самое лучшее, плюс имеет дополнительные фишки. Поэтому, если вы знакомы с OllyDbg, то довольно быстро освоитесь в x64dbg.
3. Заключение
Вот и вы и познакомились с функциями CreateFont и CreateFontIndirect. Теперь вы знаете, что они используются для создания логического шрифта, который является неотъемлемой частью любой программы. Узнали почему появляются кракозяблики и, надеюсь, научились их исправлять.
Но на этом эпопея с некорректным отображением кириллицы еще не заканчивается. Есть еще две функции API, которые могут стать причиной кракозябриков. Это функция MultiByteToWideChar — выполняет преобразование мультибайтовых символов строки в широкобайтовые (ANSI -> Unicode), и функция WideCharToMultiByte — выполняет преобразование широкобайтовых символов строки в мультибайтовые (Unicode -> ANSI). Но про них мы поговорим в следующий раз.
10.05.2015
